April 16, 2023
Introduction
This is a kaggle competition to predict which passengers are transported to an alternate dimension. The data source is from https://www.kaggle.com/competitions/spaceship-titanic
I blended predictive results using Vote Classfifier from two algorithms – LGBM, and CatBoost – to maximize accuracy of the prediction.
Achievement
- R-squared for test dataset after submission was 0.80897
- Rank: 133/2504 (Top 5% as of April 17, 2023)
Datasets
- 12 variables for each passenger and a column for succesfully transported or not (y variable). Total 8,693 rows for training set, 4,277 rows for test set.
- After data cleaning, I kept all rows and imputed missing values.
Language and libraries
Language : Python
Libraries :
- Data Manipulation: pandas, numpy
- Data Visualization: matplotlib, seaborn, msno
- Machine Learning: sklearn, xgboost, lightgbm, catboost
Data Preprocessing 1
- Insights :
- Missing data is not in order
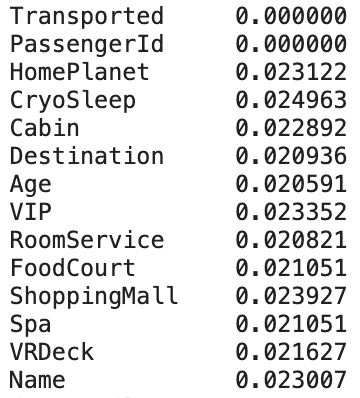
Check percetage and distribution of missing values (i.e. Data Sparcity):
- By missingno visualization, there is no specific trend or pattern in the distribution of missing values.
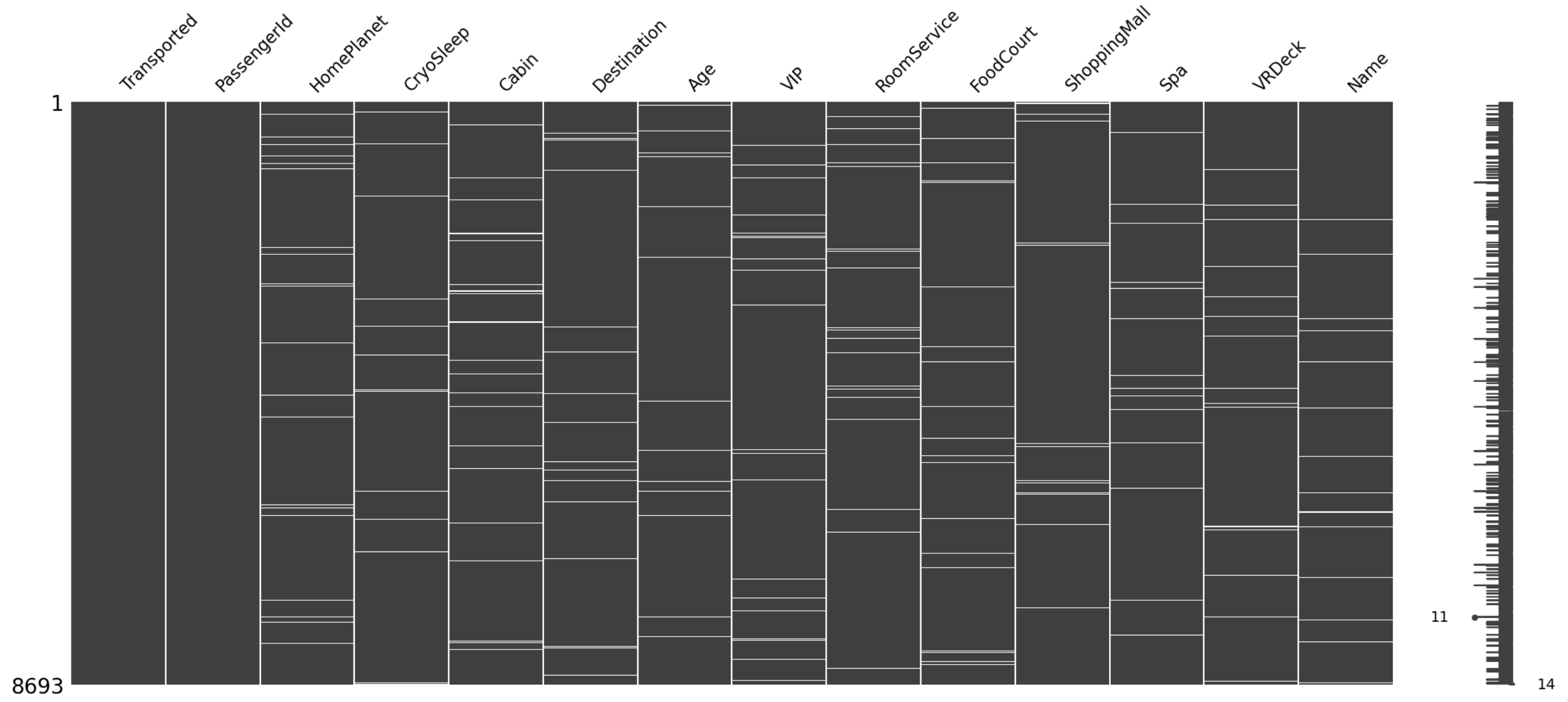
- There are no features with missing values over 5%.
Separate “PasssengerID”
- Extract number after “_” in PassegerID columns as Family number
- e.g. original foramt “9280_02” –> “9280” as PassengerID & “02” as Family number
Separate “Cabin”
- Split Cabin columns into Cabin_deck, Cabin_num, Cabin_side
Convert to correct data type
Categorical
- HomePlanet: Earth, Europa, Mars
- Cabin: 3 components - cabinet deck / number / side
- Destination: 3 in total
- Cabin_deck: categorize by letters
- Cabin_side: P or S
Numerical
- Age: not normal distribution
- RoomService: need transformation (highly right skew)
- FoodCourt: need transformation (highly right skew)
- ShoppingMall: need transformation (highly right skew)
- Spa: need transformation (highly right skew)
- VRDeck: need transformation (highly right skew)
- Cabin_num
Boolean
- CryoSleep
- VIP: imbalanced (most of False, but should be fine)
New data information look like below.
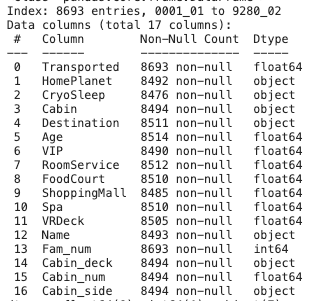
EDA (Exploratory Data Analysis) and Feature Selection
- Visualize correlation between all features
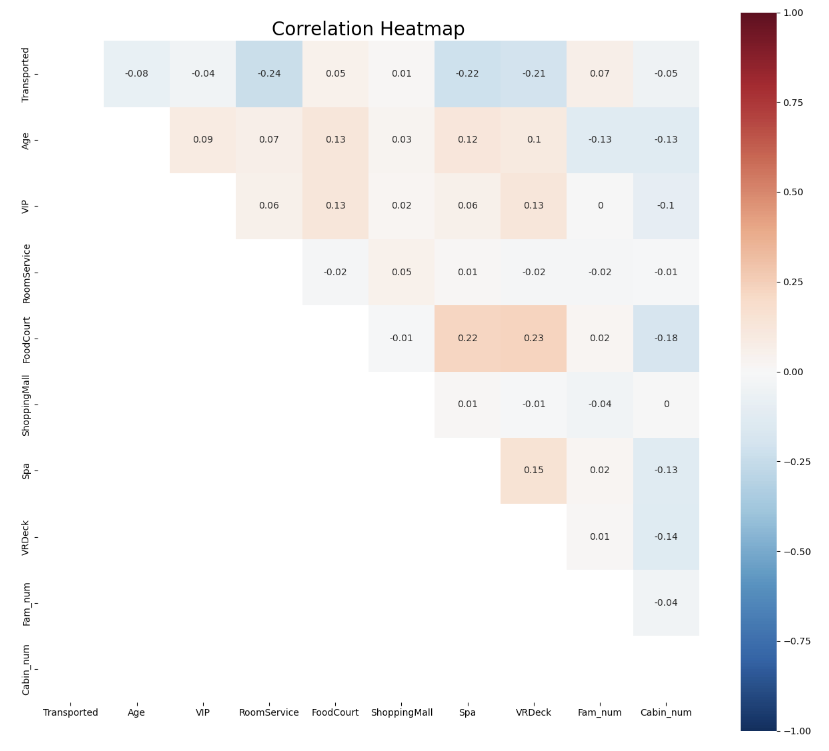
There is no strong correlation between independent and dependent variables, so it may not achieve a good performance if use linear regression only.
- Check the pairplot

There might need some transformation if using Linear regression models.
Feature Engineering
- Lux_exp: sum up of the uneccessary spending such as RoomService, Spa, and VRDeck. This may indirectly represent wealthiness.
- Total_exp: sum up of Lux_exp, FoodCourt, and ShoppingMall. This is another feature representing wealthiness.
- costly: split Total_exp into 2 levels (‘costly_False’, ‘costly_True’) by quantile for imputing missing values of CryoSleep
- CryoSleep: Indicates whether the passenger elected to be put into suspended animation for the duration of the voyage. It might be an important feature because the suspended animation may affect significantly in the process of tele-transportation. Impute missing values as 0 when passengers are not rich (i.e. costly_False in costly) and as 1 when passengers are rich.
Data Preprocessing 2 - Deal with missing values in pipeline
- Impute with most frequent values
- HomePlanet, VIP, Cabin_deck, Cabin_side, costly
- Impute with least frequent values:
- Destination (‘PSO J318.5-22’) as both nan and this value fail to transport
- Impute with median
- Age, RoomService, FoodCourt, ShoppingMall, Spa, VRDeck, Fam_num, Cabin_num, Lux_exp, Total_exp
- Impute with feature engineering
- CryoSleep
Model Build-up
-
Split Data: 85% training set, 15% test set (validation actually)
- Pipeline
- Feature pipeline: use pipeline to connect data preprocessing among different features
- Drop features
- Numerical features: simple impute to median
- Categorical features for most frequent: simple impute to most frequent value, and do one-hot encoding
- Categorical features for least frequent: simple impute to most frequent value, and do one-hot encoding
-
Binary features: impute with 0 and do one-hot encoding
- Model pipeline: After building up feature pipelines, I connected them to the model or algorithms, so I don’t need to do the same task again on test data set.
Model Selection
After trying a bunch of algorithm, the Light GBM, and Catboost perform better.
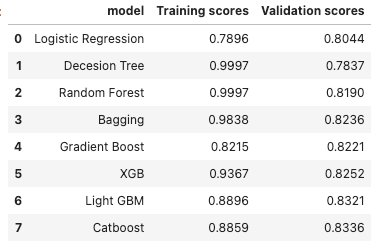
I then decide to combine them together to see if it is possible to achieve better accuracy.
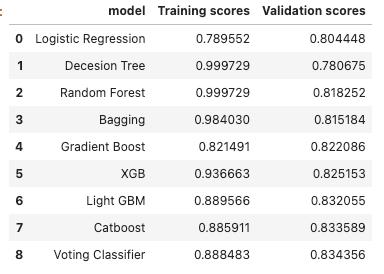
It turns out that the validation score is better than other two. After submitting, however, the results from catboost and LightGBM is better than that from voting classifier. It might be because of data leakage when training those algorithms.
Evaluation
- R-squared: all the scores is evaluated based on R-squared.
- Feature importances on Catboost:
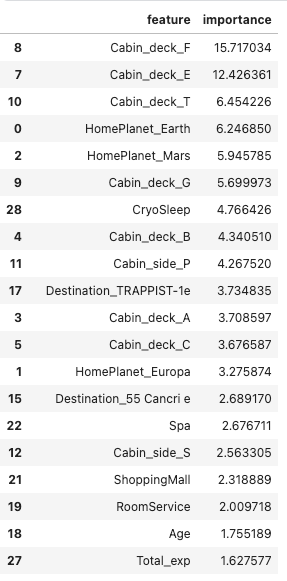
It seems CryoSleep is not the most important but still the top 7th.
Potential future improvement
- Semi-supervised learning: when imputing the missing value, doing semi-supervised learning may be helpful. It can prevent from losing information and still relatively maintain the accuracy.
- Write another data preprocessor for Catboost algorithm: Writing another data preprocessor without one-hot encoding might be helpful for Catboost because catboost algorithm has a built-in function for categorical features. Leaving this step to a well designed algorith might be better.
Takeaways
- First try to blend results from different models
- First try using advanced Gradient Boosting algorithm other that XGB
- Voting Classifier is not helpfull all the time: When combining multiple algorithms with Voting classifier, it might not be always good because some algorithms outperform others or because the beneifts of algorithms would cancel out each other. In this case, those single algorithms such as Catboost and LightGBM perform better than Voting classifier.
Code
For code detail, you can check Kaggle here or Github here.